- O modelo de linguagem DeepSeek-R1 foi desenvolvido com aprendizado por reforço, permitindo que aprenda a raciocinar sem exemplos humanos.
- O modelo gera respostas mais precisas, mas enfrenta desafios de legibilidade.
- A equipe do DeepSeek AI publicou um estudo na revista Nature, detalhando o treinamento do modelo.
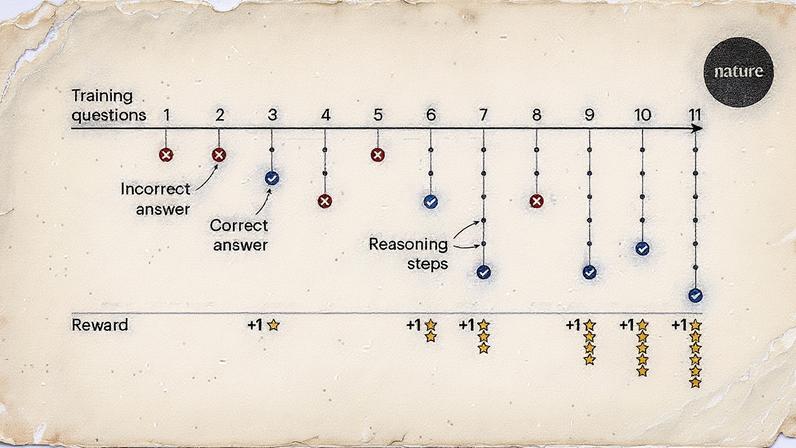
- O DeepSeek-R1 é eficaz em resolver problemas matemáticos e de programação, utilizando um sistema de pontuação para autoavaliação.
- Apesar dos avanços, o modelo ainda apresenta dificuldades em manter a clareza nas respostas, levando a um treinamento em múltiplas etapas.
Os modelos de linguagem grandes (LLMs) têm se destacado em tarefas complexas ao elaborarem seu raciocínio antes de fornecer respostas. Um novo modelo, o DeepSeek-R1, foi desenvolvido com aprendizado por reforço, permitindo que LLMs aprendam a raciocinar sem exemplos humanos. Essa abordagem resulta em respostas mais precisas, embora ainda enfrente desafios de legibilidade.
A equipe do DeepSeek AI publicou um estudo na revista *Nature*, onde descreve como o modelo foi treinado para produzir raciocínios de forma autônoma. Em vez de depender de instruções ou exemplos humanos, o modelo utiliza um sistema de pontuação que recompensa respostas corretas e penaliza as incorretas. Essa técnica, semelhante ao aprendizado de crianças em jogos, permite que o LLM desenvolva sua própria forma de raciocinar.
Aprendizado por Reforço
O DeepSeek-R1 foi projetado para resolver problemas matemáticos e de programação, onde as respostas são verificáveis. Durante o treinamento, o modelo aprendeu que raciocinar aumentava suas chances de acerto, levando-o a se autoavaliar e corrigir suas respostas. Essa capacidade de auto-reflexão é um avanço significativo em relação a métodos anteriores, que muitas vezes introduziam viés ao basear-se em exemplos humanos.
Entretanto, o modelo também apresentou comportamentos que dificultam a compreensão de suas respostas. Em alguns casos, o LLM alternou entre idiomas e gerou traços de raciocínio excessivamente longos. Para mitigar esses problemas, os pesquisadores implementaram um treinamento em múltiplas etapas, combinando aprendizado por reforço e supervisionado, resultando em um desempenho superior em tarefas de linguagem.
Desafios e Avanços
Os pesquisadores destacam que, apesar dos avanços, a questão sobre o que constitui um bom raciocínio em LLMs é complexa. O DeepSeek-R1 evoluiu de um solucionador poderoso, mas opaco, para um sistema que pode manter conversas mais naturais. Essa transformação reflete a necessidade de sistemas de IA que não apenas resolvam problemas com precisão, mas que também sejam compreensíveis e confiáveis para os usuários.






Entre na conversa da comunidade