- O modelo DeepSeek-R1-Zero foi lançado como uma inovação em inteligência artificial, utilizando aprendizado por reforço puro.
- Ele desenvolveu habilidades de raciocínio avançadas sem depender de anotações humanas, superando modelos tradicionais.
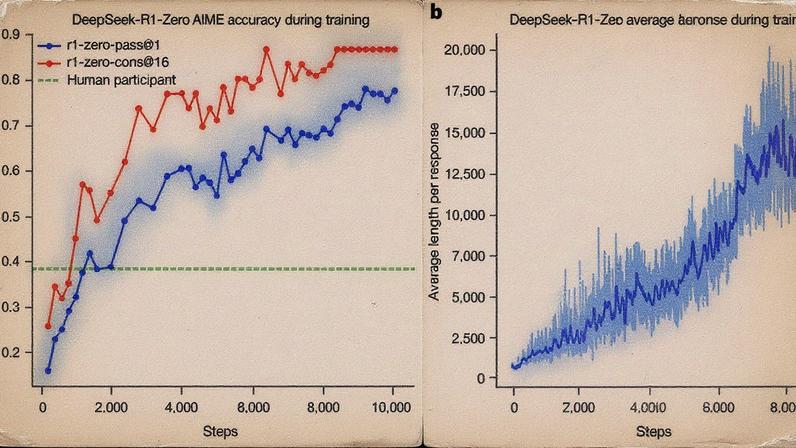
- O desempenho do modelo em tarefas complexas, como matemática e programação, alcançou uma taxa de acerto de 77,9% no American Invitational Mathematics Examination (AIME) 2024, um aumento significativo em relação a 15,6%.
- O DeepSeek-R1-Zero também se destacou em competições de codificação e em áreas como biologia, física e química, mas enfrenta desafios de legibilidade e mistura de idiomas.
- A equipe lançou o DeepSeek-R1, que melhora a consistência linguística e a capacidade de seguir instruções, além de disponibilizar modelos destilados ao público para pesquisa em inteligência artificial.
Avanços em Inteligência Artificial: DeepSeek-R1-Zero Revoluciona o Raciocínio Autônomo
Recentemente, o modelo DeepSeek-R1-Zero foi apresentado como uma inovação significativa na área de inteligência artificial. Treinado com aprendizado por reforço puro, o modelo desenvolveu padrões de raciocínio avançados sem a necessidade de anotações humanas, superando modelos convencionais em tarefas complexas.
A capacidade de raciocínio geral é um desafio persistente na inteligência artificial. Embora os modelos de linguagem grandes (LLMs) tenham mostrado avanços, como os métodos de chain-of-thought (CoT), eles ainda dependem de demonstrações humanas extensivas. O DeepSeek-R1-Zero, por outro lado, utiliza um framework de aprendizado por reforço que incentiva o desenvolvimento de habilidades de raciocínio emergentes, como auto-reflexão e verificação.
Desempenho Superior
O modelo demonstrou desempenho superior em tarefas verificáveis, incluindo matemática e programação, alcançando uma taxa de acerto de 77,9% no American Invitational Mathematics Examination (AIME) 2024. Essa taxa representa um aumento significativo em relação ao desempenho inicial de 15,6%. Além disso, o DeepSeek-R1-Zero se destacou em competições de codificação e problemas complexos nas áreas de biologia, física e química.
A abordagem de aprendizado por reforço permitiu que o modelo gerasse respostas mais longas e complexas, incorporando estratégias de verificação e reflexão. Embora o DeepSeek-R1-Zero tenha mostrado excelentes capacidades de raciocínio, ele enfrenta desafios como legibilidade e mistura de idiomas, frequentemente combinando inglês e chinês em suas respostas.
Evolução e Melhoria
Para abordar essas limitações, a equipe desenvolveu o DeepSeek-R1, que integra um framework de aprendizado em múltiplas etapas. Este novo modelo não apenas herda as capacidades de raciocínio do DeepSeek-R1-Zero, mas também melhora a consistência linguística e a capacidade de seguir instruções. O treinamento do DeepSeek-R1 combina amostras de dados de raciocínio e não raciocínio, permitindo um desempenho aprimorado em tarefas gerais de geração de linguagem.
Os modelos destilados do DeepSeek-R1 também foram disponibilizados ao público, oferecendo acesso a poderosas capacidades de IA a um custo energético reduzido. A equipe acredita que esses modelos contribuirão significativamente para a pesquisa, promovendo o desenvolvimento de modelos de raciocínio mais poderosos e compreensíveis.
Com o avanço das técnicas de aprendizado por reforço, o futuro da inteligência artificial parece promissor, com a possibilidade de modelos superarem as capacidades humanas em tarefas complexas. A integração de ferramentas externas e a evolução contínua dos modelos são áreas que prometem expandir ainda mais as fronteiras do que a IA pode alcançar.






Entre na conversa da comunidade